
Biostatistik angewendet auf ODF
Einführung :
Die Statistik ist im medizinischen Bereich zu einer wesentlichen Disziplin für die klinische und Grundlagenforschung geworden.
Dies ist häufig bei der Konsultation bibliografischer Referenzen der Fall und erfordert daher, den Wert der vorgeschlagenen Werke zu verstehen und ggf. zu kritisieren.
Wenn der Kieferorthopäde selbst eine Studie durchführen muss, bei der es um Statistiken geht, muss er sich davon überzeugen können, dass er die Informationen des Statistikers versteht und dass dieser sie auch richtig verstanden hat.
- 1. Definition:
Biostatistik ist eine Disziplin, die statistische Methoden zur Lösung von Problemen in Biologie und Medizin nutzt.
Sie spielt eine wichtige Rolle bei der Erhebung, Analyse und Interpretation von Gesundheitsdaten, um das Verständnis von Krankheiten und die Entwicklung neuer Behandlungsmethoden zu verbessern.
Biostatistik angewendet auf ODF
- 2. Grundlegende Konzepte:
- Population : Dies ist die Menge aller Individuen, für die wir ein oder mehrere Merkmale bestimmen möchten. Jedes Individuum unterscheidet sich von den anderen. , sehr oft ist die Population groß.
- Das Individuum : Auch statistisches Element oder Einheit genannt. Es ist die grundlegende elementare Einheit, die der Statistiker beobachtet. Dies kann ein Mensch, eine biologische oder anatomische Einheit (Patient, Zahnbogen, Ohr etc.) sein .
- Stichprobe : Es handelt sich um eine Teilmenge einer Population endlicher Größe, einen Bruchteil der untersuchten Population, dessen Größe absichtlich reduziert wurde. Damit die Ergebnisse auf die Grundgesamtheit verallgemeinert werden können, muss die Stichprobe für diese repräsentativ sein.
- Die repräsentative Stichprobe : Dies ist eine Stichprobe, deren Zusammensetzung mit der der Grundgesamtheit übereinstimmt; sie muss deren Zusammensetzung und Komplexität getreu widerspiegeln. Der einfachste Weg, eine repräsentative Stichprobe zu bilden, besteht darin, die Stichprobenteilnehmer nach dem Zufallsprinzip aus der Grundgesamtheit auszuwählen.
- Die Variable (Eigenschaft) : Im Gegensatz zu einer Konstanten, also einer Eigenschaft, die für alle Individuen den gleichen Wert hat, hat eine Variable notwendigerweise mehr als eine Modalität. Es kann quantitativ (Winkel-SNA, Überbiss usw.) oder qualitativ (atypisches Schlucken) sein.
- Die Modalitäten : sind die verschiedenen Kategorien, die eine Variable aufweisen kann.: Das Geschlecht ist eine Variable mit zwei Modalitäten, männlich und weiblich, „dichotome Variablen“, weil sie vom Typ „entweder“ sind. Variablen mit mehr als zwei Kategorien, wie beispielsweise „Blutgruppe“, werden als multichotom bezeichnet.
- 3. Deskriptive Statistik:
- Definition:
Es handelt sich dabei um eine Reihe von Werkzeugen zur Beschreibung und Analyse von Phänomenen, die gezählt und klassifiziert werden können; ihr Ziel ist die Beschreibung , nicht die Erklärung .
Es ermöglicht die Erfassung und Darstellung von Daten in Tabellen oder Diagrammen sowie die Synthese, Verarbeitung und Interpretation der gesammelten Informationen, um den Erkenntnisgewinn zu erleichtern.
- Die Variablen:
3.2.1 Qualitative Variablen:
Qualitative Variablen sind nicht messbare Variablen , sie haben keinen numerischen Wert, ihre Werte sind Qualitäten, sie werden in Worten ausgedrückt.
Wir unterscheiden:
- Nominale qualitative Variablen : (Blutgruppe, Geschlecht, Augenfarbe usw.).
- Ordinalqualitative Variablen : die in aufsteigender oder absteigender Reihenfolge klassifiziert werden können (Bildungsniveau: Bac+3, Bac+4, Bac+5 usw.).
3.2.2 Quantitative Variablen:
Quantitative Variablen sind messbar , sie sind durch numerische Werte charakterisiert. Wir unterscheiden:
- Kontinuierliche quantitative Variable : Sie hat eine unendliche Anzahl möglicher Werte, zwischen zwei unterschiedlichen Werten gibt es immer einen möglichen Zwischenwert. Dies ist für alle Variablen der Fall, die physikalische Mengen messen: Größe, Gewicht, Alter usw.
- Diskrete (diskontinuierliche) quantitative Variable : Sie hat eine endliche oder zählbare Anzahl möglicher Werte, diese Werte sind verschieden und getrennt, es sind keine Zwischenwerte möglich. Exp.: Anzahl der Zähne im Zahnbogen, Herzfrequenz.
- Darstellung einer statistischen Reihe:
3.3.1 Tabellarische Darstellung:
Eine Tabelle wird verwendet, um einen Datensatz in aggregierter, synthetischer Form darzustellen. Es muss einfach sein , es muss alle zum Verständnis notwendigen Informationen enthalten, es ist in sich selbst ausreichend .
Wir unterscheiden:
- Die statistische Tabelle mit einem Eintrag : Dies ist die einfachste, sie besteht aus zwei oder drei Spalten, wobei die erste Spalte die Werte des untersuchten Merkmals betrifft, die zweite Spalte die Zahlen und die dritte Spalte die relativen Häufigkeiten oder Prozentsätze.

Biostatistik angewendet auf ODF
- Die doppelte statistische Tabellenkalkulation : An derselben Einheit können wir zwei oder mehr Merkmale beobachten.

Verteilung der männlichen Kinder in der Kinderabteilung
3.3.2 Grafische Darstellung:
Durch die grafische Darstellung können Daten in einer klaren und präzisen visuellen Form präsentiert und schnell interpretiert werden .
Es vermittelt einen Gesamtüberblick über die Ergebnisse, gibt Aufschluss über die allgemeine Form der Verteilung und erleichtert so die Interpretation der erfassten Daten.
Das Diagramm sollte einfach, klar und für sich verständlich sein .
Die grafische Darstellung hängt von den Eigenschaften der untersuchten Daten, ihrer Art und Größe ab:
- Grafische Darstellung in Orgelpfeifen : Sie besteht aus getrennten vertikalen Stäben oder Orgelpfeifen (zwischen zwei Stäben wird ein gleichbleibender Abstand eingehalten).
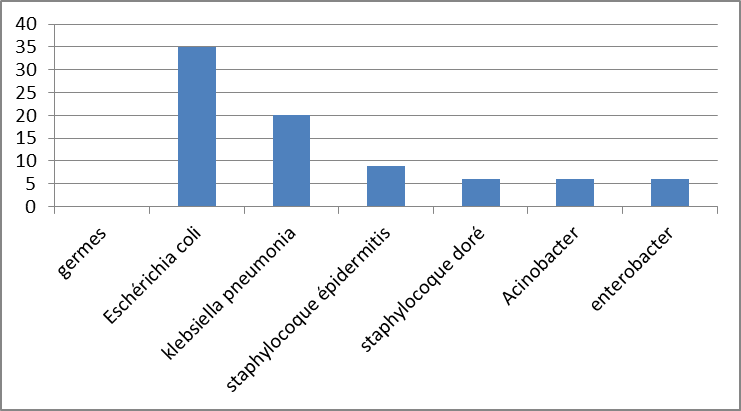
Biostatistik angewendet auf ODF
Häufigkeit von Keimen, die Wundinfektionen verursachen
- Darstellung in Form eines Kreisdiagramms „Camembert“ : Wir zeichnen einen in Sektoren unterteilten Kreis, jeder Sektor stellt eine Modalität der Variablen dar.
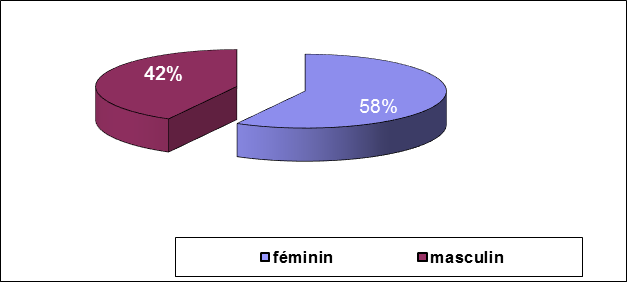
Verteilung der Patienten nach Geschlecht.
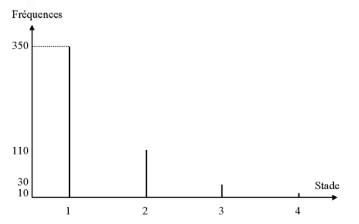
Verteilung nach Krankheitsstadium
- Grafische Darstellung im „Balkendiagramm“ : Dabei werden auf der Abszisse die Werte und auf der Ordinate die Häufigkeiten bzw. Zahlen dargestellt.
- Grafische Darstellung „Histogramm“ : Es besteht aus zusammenhängenden, nebeneinander angeordneten vertikalen Balken; Auf der Ordinate sind die Zahlen und auf der Abszisse die Klassen der Variablen dargestellt.
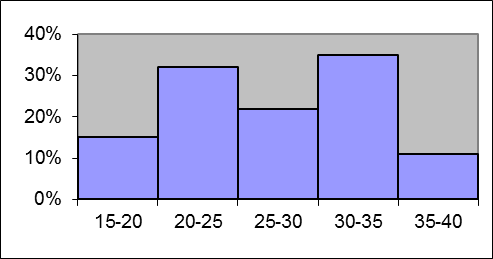
Biostatistik angewendet auf ODF
Verteilung der Drogenabhängigen nach Alter
- Charakterisierung ordinaler Daten:
3.4.1 Absolute Häufigkeit
Die absolute Häufigkeit ist die Anzahl der Personen, die einer bestimmten Modalität einer Variablen entsprechen. Beispiel: Wir haben aus einer Gruppe von 180 Probanden die Individuen gezählt, die den verschiedenen Skelettklassen angehörten.
| Klasse I | Klasse II | Klasse III |
| 98 | 52 | 30 |
Beschreibung der kieferorthopädischen Probe
3.4.2 Relative Häufigkeit:
Wir können die relativen Häufigkeiten bestimmen, die für jede Klasse das Verhältnis ihrer Größe zur Gesamtzahl der Individuen in der Messreihe darstellen. Die Summe der relativen Häufigkeiten ergibt 1. Manchmal werden die Ergebnisse als Prozentsatz ausgedrückt.
Klassengröße
Relative Häufigkeit = ————————————– x 100
Gesamtbelegschaft
| Klasse I | Klasse II | Klasse III |
| 45 % | 29 % | 17 % |
Relative Häufigkeiten in Prozent
3.4.3 Kumulative Häufigkeiten:
Sie werden für ordinale Daten verwendet, die geordnete Klassen aufweisen . Sie werden sowohl für Zahlen als auch für relative Häufigkeiten berechnet.
Sie ermöglichen es uns, anzugeben, bei wie vielen Personen ein Wert größer oder kleiner als ein vorgegebener Wert ist.
Beispiel: Die Verteilung der 80 Patienten, die diesen Monat zur ODF-Konsultation eingeliefert wurden, nach Alter.
Biostatistik angewendet auf ODF
| Alter (Jahre) | Absolute Häufigkeit | Relative Häufigkeit % | Kumulative Häufigkeit % |
| 08 – 10 | 10 | 12,5 % | 12,5 % |
| 10 – 12 | 50 | 62,5 % | 75 % |
| 12 – 14 | 20 | 25 % | 100 % |
Verteilung der Patienten in der ODF-Sprechstunde nach Alter.
- Positionsindizes:
3.5.1 Der Durchschnitt:
Der „durchschnittliche“ Wert entspricht dem Quotienten aus der Summe aller Werte der Reihe und der Gesamtzahl.
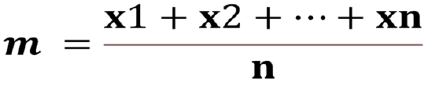
Es werden zwei weitere Positionsindizes verwendet:
3.5.2 Der Median
Dies ist die Zahl, die die statistische Reihe in zwei gleich große Teile teilt.
3.5.3 Der Modus
Der häufigste Wert einer statistischen Reihe ist der Wert (die Werte) des Merkmals, dessen Anzahl am größten ist.
- Dispersionsparameter:
3.6.1 Varianz:
Es gibt an, wie die statistische Reihe oder Zufallsvariable um ihren Mittelwert oder Erwartungswert streut.
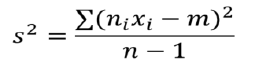
3.6.2 Standardabweichung
Dies ist die am häufigsten verwendete Dispersionseigenschaft, da sie am zufriedenstellendsten ist.

- Epidemiologische Studien:
- Arten von Studien in der Epidemiologie:
Es gibt drei Arten von Studien, die drei verschiedene Fragen beantworten:
- Deskriptive Studien, die den Gesundheitszustand der Bevölkerung beschreiben sollen
- Analytische Studien, die den Zusammenhang zwischen einem Risikofaktor und dem Auftreten einer Krankheit verstehen wollen
- Evaluationsstudien mit dem Ziel, unter mehreren Strategien die wirksamste Intervention oder Behandlung zu ermitteln.
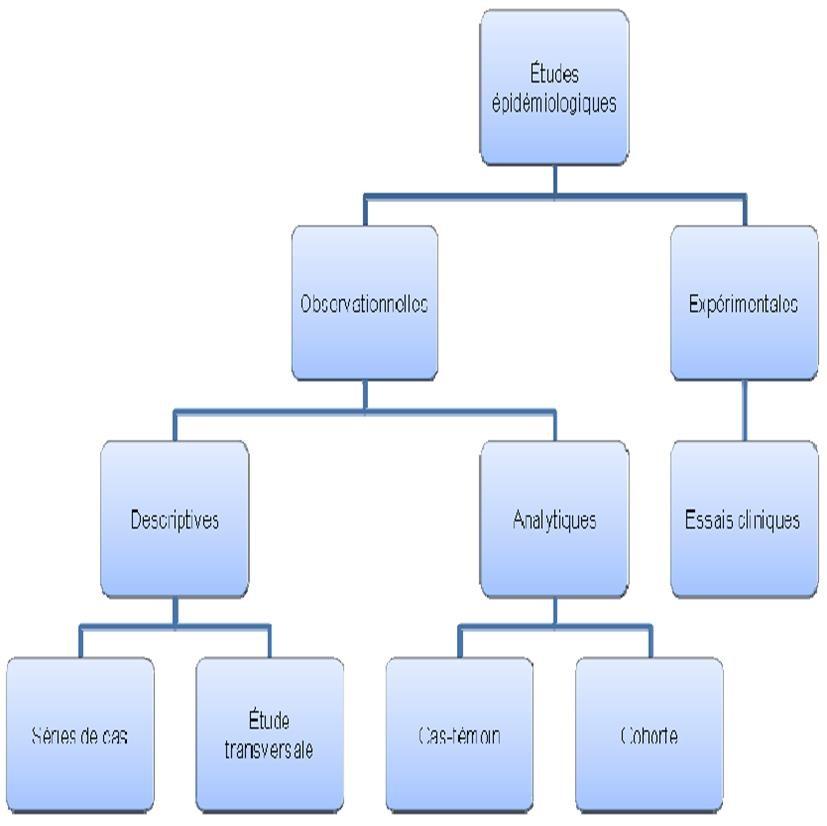
- Pyramide des Niveaus wissenschaftlicher Beweise
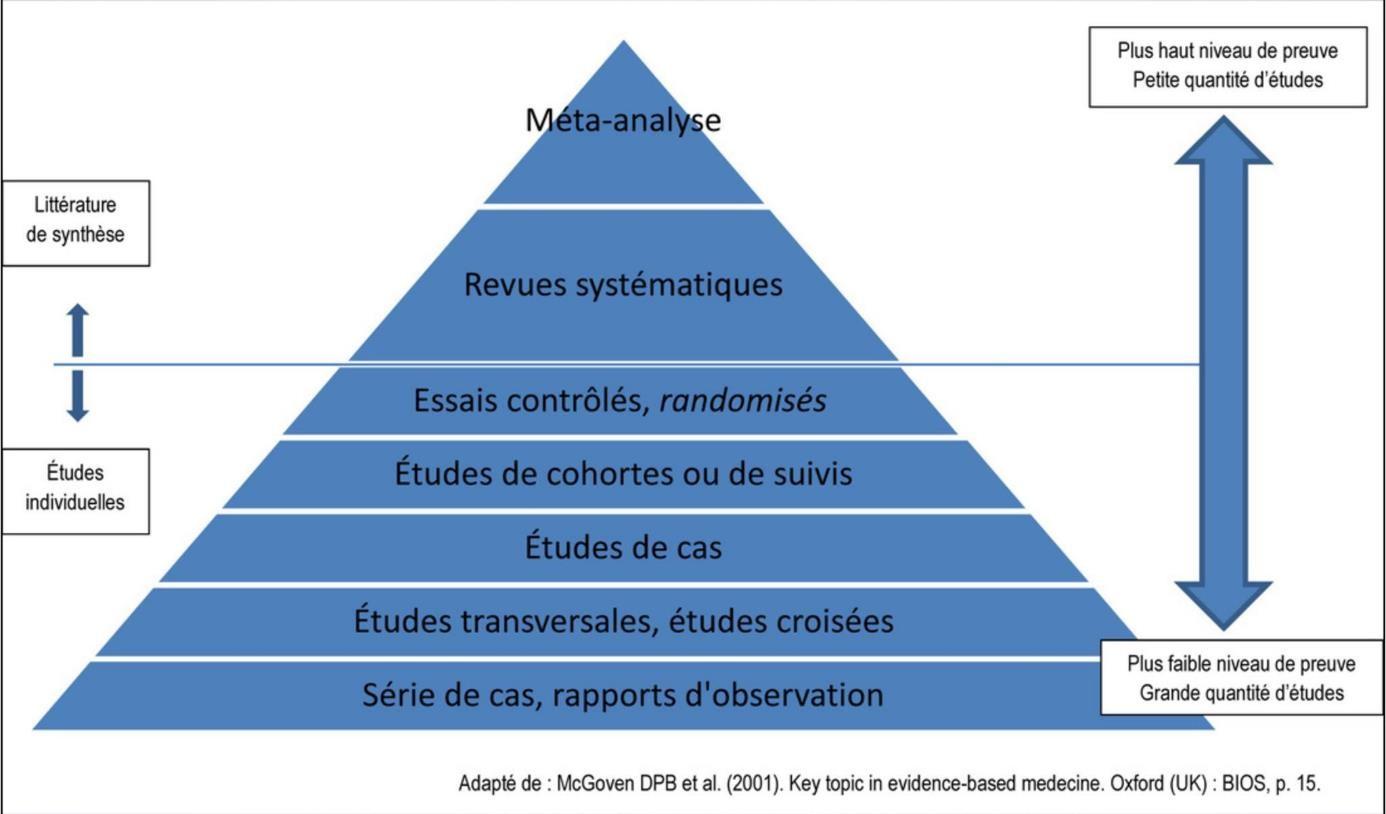
Biostatistik angewendet auf ODF
- Der statistische Test:
- Definition:
Es handelt sich um einen Test, der den Vergleich verschiedener Parameter (Varianz, Mittelwert) ermöglicht. um eine statistische Hypothese auf der Grundlage einer aus einer Population entnommenen Stichprobe zu bestätigen oder zu widerlegen.
Anhand der Berechnungen auf Grundlage der Daten aus dieser Stichprobe können wir Rückschlüsse auf die ursprüngliche Hypothese ziehen: Ist sie akzeptabel oder widerlegbar ?
Der statistische Test ermöglicht uns auch festzustellen, ob der Unterschied zwischen unseren beobachteten Daten und den Bevölkerungsdaten einfach auf Stichprobenschwankungen zurückzuführen ist oder ob tatsächlich ein Unterschied besteht.
- Die wichtigsten verwendeten Tests:
- X²-Test (KHI-2) • Fischer-Test
- Student-T-Test
- ANOVA-Test
- MacNemar-Test
- Kolmogorov-Smirnov-Test
- Mann-Whitney-Test
- Häufigkeit bestimmter Anomalien in ODF:
- Skelettale Klasse III : Die Häufigkeit ist gering und liegt bei 2 bis 8 % der kieferorthopädischen Bevölkerung (DEMOGE).
- Klasse II/1 : Sehr häufig; ¾ der kieferorthopädischen Bevölkerung.
- Klasse II/2 : Relativ selten, betrifft 2 bis 3 % der Gesamtbevölkerung und kommt bei nicht mehr als 10 % der kieferorthopädischen Bevölkerung vor.
- DDM : Betrifft 50 % der kieferorthopädischen Bevölkerung (BOUVET).
- Agenesie : Die Prävalenz variiert je nach Studien zwischen 2,6 % und 11,3 %,
- Überzählige Zähne : Die Prävalenz variiert zwischen 0,15 % und 3,9 %.
- Lippenspalten und Kieferspalten : Sie kommen häufig vor, Inzidenz = 1/1000.
- Abschluss :
Statistiken sind im medizinischen Bereich von wesentlicher Bedeutung. Sie werden verwendet, um:
Beherrschen Sie das Lesen und Verstehen biomedizinischer wissenschaftlicher Literatur, in der in großem Umfang auf Statistiken zurückgegriffen wird.
Ermöglichen Sie eine kritische Lektüre der Artikel
Verbessern Sie den Gesundheitssektor, indem Sie es Ärzten ermöglichen, die aus dieser Forschung resultierenden Richtlinien und Empfehlungen für eine angemessene Versorgung zu befolgen.